_아침독서상단(2).jpg)
.jpg) |
.jpg) |
.jpg) |
| 2024년 02월 4주차 |
BOOK SUMMARY
 |
||
 |
수학의 매력 |
|
| 저자 리여우화 (지은이), 김지혜 (옮긴이) 출판 미디어숲 출간 2024.01 |
||
 흥미로우면서도 이해하기 쉬운 사례와 문제로 보는 수학의 본질과 쓸모 흥미로우면서도 이해하기 쉬운 사례와 문제로 보는 수학의 본질과 쓸모 |
||
도서요약 보기수학의 매력 만물은 수이다 가장 효율적인 언어? 가장 ‘효율’적인 언어가 있을까? 예를 들어, ‘해리 포터’의 다양한 언어 버전 중에서도 중국어 버전이 항상 가장 얇다. 그렇다면 중국어가 가장 효율적인 언어라는 견해는 과학적인가? 이에 과학자들이 언어의 효율성을 가늠하고 정량적으로 분석할 수 있는 방법을 찾아냈는데 바로 ‘정보 엔트로피’이다. 1948년, 미국의 수학자 클로드 섀넌(Claude Shannon)은 부호 시스템에서 단위 부호의 평균 정보량을 나타내는 지표인 정보 엔트로피를 제시하고, 또한 정보 엔트로피를 계산하는 공식을 다음과 같이 설명하였다. 정보 엔트로피 = - Σ p(i) log2p(i) 공식에서 pi는 특정 부호 시스템에서 특정 부호가 출현하는 빈도이다. 빈도는 특정 텍스트에 나타나는 특정 단어의 비율이다. 만약 100만 자로 구성된 책에서 어떤 글자가 1만 번 출현했다면, 이 글자의 빈도는 1만/100만=0.01=1퍼센트인 것이다. 섀넌의 공식은 특정 부호 시스템의 부호 빈도를 모두 계산해 위의 공식에 대입하는 것으로, 이것이 바로 부호 시스템의 정보 엔트로피이다. 이는 좀 추상적으로 들릴 수도 있겠지만, 실제 연산을 하면 이해하기 쉽다. 예를 들어 부호 시스템에 부호가 하나만 있으면 정보 엔트로피는 어떻게 될까? 부호가 하나밖에 없기 때문에 그 빈도는 100% 즉, 1이 될 수밖에 없다. 1의 로그는 0이므로 이 공식에 따르면 계산 결과는 0이 된다. 정보 엔트로피에 영향을 미치는 두 가지 요인은 부호의 개수와 부호의 빈도 분포이다. 우리는 한 변수를 고정하여 다른 변수가 정보 엔트로피에 미치는 영향을 확인해 볼 수 있다. 즉, n개의 부호를 가진 부호 시스템의 정보 엔트로피는 log2n이다. 부호가 많을수록 정보 엔트로피는 커지는데, 부호의 수가 일정하고 부호의 빈도 분포가 바뀌면 정보 엔트로피는 어떻게 될까? 조금만 계산해 봐도 부호의 빈도 분포가 고르지 않을수록 정보의 엔트로피가 작아진다는 것을 알 수 있다. 부호가 두 개뿐이라고 할 때, 그중 하나의 출현 빈도가 90%라면, 다른 하나는 10%에 불과해 이를 공식에 대입하면, 부호 시스템의 정보 엔트로피는 0.47 정도로 계산된다. 앞서 두 부호의 빈도가 같으면 정보 엔트로피는 1이었다. 부호가 많을수록 정보 엔트로피는 큰 값을 가지는데, 단일 부호가 제공하는 정보도 더 많다고 할 수 있을까? 한자 시스템은 몇천 개의 모음을 가진 부호 시스템과 비슷하기 때문에 한자에서 한 글자의 정보 엔트로피는 영문자보다 높을 것이다. 즉, 부호의 빈도가 균일할수록 여러 부호 사이의 관련성이 작아지고 각 부호는 모두 매우 중요해서 빠뜨릴 수 없기 때문에 단일 부호의 정보량이 많아져 정보 엔트로피가 커진다. 반대로 부호가 나타내는 관련성이 클수록 일부 부호는 생략할 수 있는데, 이는 이러한 부호가 제공하는 정보의 양이 적다는 것을 의미한다. 예를 들어 영어 단어 중 ‘ing’, ‘tion’ 등이 나타나는 경우가 많다. 이들 조합에서는 글자 하나를 빠뜨리거나 순서가 틀려도 읽는 데 방해가 되지 않는다. 중국어는 각 글자의 연관성이 적어 한 문장에서 여러 글자가 누락되면 그 문장의 원래 뜻을 알아맞히기 힘들다. 글자 사이의 연관성이 적다는 것은 글자 간의 출현 빈도 차이가 크지 않다는 것이고 그다음에 오는 글자를 예측하기 어렵다는 것을 의미한다. 따라서 한 글자당 제공하는 정보 엔트로피는 크다. 그렇다면 영어와 중국어의 정보 엔트로피는 도대체 얼마나 될까? 2019년 해외 유명 수학 블로거 존 D. 쿡(John D. Cook)은 자신의 블로그에 중국어의 정보 엔트로피를 계산한 글을 남겼다. 그가 사용한 중국어 단어 빈도 데이터는 2004년 미국의 한 대학의 연구자 준 다(Jun Da)가 인터넷에 올린 것으로, 통계자료에서 가장 많이 나타나는 중국어 한자 1위는 ‘더’로 약 4.1%, 2위는 ‘이’로 나타났으나 빈도는 1.5%에 불과했다. 쿡은 이 단어의 빈도에 근거하여 단일 한자의 정보 엔트로피를 9.56으로 확인하였다. 일반적으로 단일 영문자의 정보 엔트로피는 3.9이므로 중국어의 정보 엔트로피는 매우 크다고 할 수 있다. 그렇다면 중국어의 정보 엔트로피가 영어보다 두 배 이상 높다고 말할 수 있을까? 정보 엔트로피의 비교는 불확실한 요소들이 있기 때문에 그렇게 간단하지 않다. 앞에서는 알파벳과 한자를 비교했는데, 영어 단어와 한자를 비교할 수도 있다. 실제로 영어 단어의 조합은 많아졌지만 한 문장의 앞뒤 연관성은 너무 많아 단어의 정보 엔트로피는 더 낮아졌고, 섀넌은 영어 단어 1개의 정보 엔트로피가 2.62에 불과하다고 계산한 바 있다. 물론 중국어에 대해서도 어구별로 통계를 낼 수 있지만, 중국어에 있어서 어떻게 단어를 자를 것인가에 대한 확실한 기준이 없다. 단어 빈도에 대한 통계도 한 요인이다. 같은 중국어라도 고대 중국어와 현대 중국어의 단어 빈도는 틀림없이 다를 것이다. 분야별로 다양한 글에서의 단어 빈도에도 큰 차이가 있을 수 있다. 다만 한 가지 확실한 것은 어느 언어를 막론하고 수학 논문의 단위 글자 정보 엔트로피는 분명히 다른 유형의 문장보다 훨씬 클 것이며, 이것도 수학 논문이 이해하기 어려운 이유 중 하나이다. 수학자는 활용하는 공식에 대한 설명을 쓰지 않고 ‘분명히’ 혹은 ‘쉽게’ 얻을 수 있는 식에 대해서 결코 해석을 덧붙이지 않는다. 어쨌든 현재 서로 다른 통계방식에서 중국어의 정보 엔트로피 값은 여전히 크다. 쿡은 서로 다른 언어를 비교할 때 새로운 비교 방식으로 각 언어가 단위 시간 내에 출력하는 정보의 양을 제기하였다. 그리고 하나의 추측을 제기했다. 서로 다른 언어의 단위 시간 내에 출력하는 정보의 양은 비슷하다. 피할 수 없는 대칭 문제 대자연의 선물 많은 책에서 메르센 소수를 다룬다. 메르센 소수를 숫자 중의 보석이라고 부르는 이유는 무엇일까? 이미 사람들이 ab-1과 같은 형식의 숫자를 알고 있는데, 만약 이 수가 소수라면 이 숫자는 2p-1꼴이어야 하고, p는 소수이어야 한다. 단, 2p-1은 소수이기 위한 필요조건일 뿐 충분조건은 아니다. 어쩌면 이것의 충분조건을 찾을 수 없기 때문에 사람들은 2p-1이 소수인지 아닌지를 일일이 체크할 수밖에 없다. 2p-1이 소수가 아닌 경우가 매우 많으므로 메르센 소수는 ‘숫자 중의 보석’으로 불릴 만큼 소중하다고 할 수 있다. 이 장에서 언급할 것은 그래프 이론의 강한 정규 그래프(strongly regular graph)이다. 강한 정규 그래프도 대자연의 선물이자 그래프 이론에서 보석이라 할 만큼 귀중하다. 그래프 이론에서 ‘그래프’는 바로 ‘점’과 그 사이를 연결하는 선인 ‘변’으로 구성된다. 점의 위치와 연결선의 모양, 길이 등은 전혀 고려할 필요가 없다. 여기서는 방향이 없는 선과 두 점 사이에 최대 한 개의 변만 있는 ‘무방향 단순그래프’만을 대상으로 단순화하여 다루려고 한다. 무엇이 강한 정규 그래프인지 이해하려면, 우리는 다음과 같은 문제부터 시작해야 한다. 9명이 있을 때 모든 사람이 서로 다른 4명을 알 수 있을까? 만약 어떤 두 사람이 서로 안다면, 다른 한 사람이 그들과 알 수 있을까? 어떤 두 사람이 서로 모른다면 다른 두 사람과 이 두 사람은 서로 알 수 있을까? 이런 문제는 듣기에 좀 까다롭지만, 경험이 있는 사람들은 ‘몇 사람은 알고 모르는’ 문제로 듣자마자 이것이 ‘그래프 문제’라는 것을 눈치챈다. 이를 ‘그래프 문제’로 바꾸면 9개의 점이 주어질 때, 각 점은 4개의 다른 점과 변으로 연결되어 있으며, 이때 각 점의 차수는 4라고 한다. 만약 두 점 사이에 연결선이 있다면, 이 두 점은 정확히 하나의 삼각형에 속하거나, 나머지 한 점이 바로 이 두 점의 이웃이라고 할 수 있다. 만약 두 점 사이에 연결선이 없다면, 이 두 점은 하나의 사각형에 속하거나, 다른 두 점과 이 두 점은 이웃이다. 이것은 그래프 이론에서 강한 정규 그래프로, 하나의 그래프에서 모든 점의 차수, 즉 모든 점의 이웃 수가 같다면 이것을 정규(regular)라고 한다. 예를 들면, 어떤 그래프에서 임의의 두 점 사이에 변이 있다면 즉, n개의 점이 있는 그래프에서 각 점의 차수가 n-1이라면 그것은 반드시 정규 그래프이고 이를 ‘완전 그래프’라고도 한다. 또 다른 정규 그래프의 예는 모든 점을 연결하여 원을 구성하는 것인데, 이 그래프에서 각 점의 차수는 2이며 이를 ‘환 그래프(Ring graph)’라고 한다. 이 두 그래프는 모두 매우 자명한 정규 그래프로 자명하지 않은 정규 그래프도 많이 있다. 다음과 같은 문제를 보자. 점이 n개인 그래프에 대하여 n과 각 점의 차수 k가 어떤 성질을 만족시킬 때 정규 그래프를 구성할 수 있을까? 강한 정규 그래프는 말 그대로 그 조건이 정규 그래프보다 강한 것으로 다음과 같은 두 가지 조건을 추가해야 한다. 1. 임의의 인접한 두 점에 대하여, 동시에 이 두 점에 인접한 점의 수는 같으며, 이 수는 그리스 문자로 표시한다. 2. 임의의 서로 인접하지 않은 두 점에 대하여, 동시에 이 두 점에 인접하는 점의 수도 같으며, 이 수는 그리스 문자로 표시한다. 그래프에서 점의 개수를 v, 각 점의 차수를 k라고 하면 (v, k, λ, μ) 4개의 매개변수가 강한 정규 그래프의 기본 특성을 결정한다. 우리는 항상 이 네 값을 이어서 쓰고 강한 정규 그래프라고 부르겠다. 이를테면 앞의 9개 점을 가지는 그래프는 ‘(9, 4, 1, 2)-강한 정규 그래프’라고 한다. 한 가지 더 설명하자면, 완전 그래프 즉, 어떤 두 점이 모두 연결된 경우는 암묵적으로 배제한다. 왜냐하면 n개의 점으로 구성된 완전 그래프는 필연적으로 (n, n-1, n-2, n-2)의 강한 정규 그래프임이 매우 자명하기 때문이다. 또한 μ=0인 경우도 제외해야 한다. 그 이유는 우리는 연결된 그래프만 고려하는데 μ=0일 때 그래프는 끊어지기 때문이다. 또 한 가지, 만약 어떤 그래프가 강한 정규 그래프라면 그것의 ‘여 그래프(complement graph)’ 또한 강한 정규 그래프이다. 여 그래프는 주어진 그래프에 어떤 변을 더 추가해야 완전 그래프가 될 때, 추가된 이 변들이 바로 원래 그래프의 여 그래프이다. v, k, λ, μ를 매개변수로 하는 강한 정규 그래프의 여 그래프는 몇 개의 매개변수가 각각 무엇인지 고려해 볼 수 있다. 요컨대, 강한 정규 그래프는 항상 쌍을 이루어 나타나는데, 그것의 여 그래프가 자기 자신인 경우는 제외한다. 우선 점 3개를 보면, 점 3개의 강한 정규 그래프는 삼각형으로, 즉 점 3개의 완전 그래프이다. 점 4개의 강한 정규 그래프는 처음으로 불완전 그래프가 나타나는 강한 정규 그래프로, 사각형이며 매개변수는 (4, 2, 0, 2)이다. 오각형도 강한 정규 그래프로 매개변수는 (5, 2, 0, 1)이다. 조금 더 생각해 보면 육각형과 그 이상의 다각형은 환(ring) 모양의 강한 정규 그래프가 없다는 것을 알게 된다. 점의 개수가 합성수이면 소인수분해를 통해 점을 몇 개의 동일한 부분으로 분해할 수 있고 강한 정규 그래프라는 것을 발견할 수 있다. 이런 강한 정규 그래프는 구조가 간단하기 때문에 재미도 없지만 다행히 이런 그래프 외에 강한 정규 그래프가 많다. 따라서 나는 이런 그래프를 ‘자명한’ 강한 정규 그래프라고 할 것이다. 7개의 점에 대해서는 강한 정규 그래프가 없는데, 아무래도 7이 소수이기 때문에 이런 강한 대칭성을 구성할 수 없기 때문이라고 생각할 수 있다. 11개 점에도 확실히 강한 정규 그래프가 없다. 그런데 점이 13개인 경우는 있다. 잠시 후 8개의 점에도 강한 정규 그래프가 없다는 것을 알 수 있다. 다음으로 13개 점으로 넘어가 보자. 앞에서는 7개의 점과 11개의 점 모두 비자명한, 즉 강한 정규 그래프가 없다고 했는데 점이 13개인 경우는 (13, 6, 2, 3)의 강한 정규 그래프 하나가 있다. 이를 ‘페일리 그래프(Paley graph)’라고 한다. 레이먼드 페일리(Raymond Paley)는 20세기 초 영국의 수학자로, 페일리 그래프의 특징은 점의 개수가 단일 소수의 거듭제곱이어야 하며, 또한 4로 나누었을 때 나머지가 1이라는 것이다. 이 조건은 4로 나누었을 때 나머지가 1인 소수이면 된다는 것을 내포하고 있는데, 13이 조건에 딱 부합한다. 이 조건에 부합하는 점은 페일리 그래프를 구성할 수 있으며 이는 필연적으로 강한 정규 그래프이다. 이것은 해밀턴 그래프로 해밀턴 회로를 포함하며 필연적으로 자기 자신이 여 그래프이고, 여 그래프는 바로 자신이다. 여기까지가 페일리 그래프의 흥미로운 성질이다. 누구든지 수학의 ‘에베레스트’에 오를 수 있다 수학자의 종이 컴퓨터 여러분은 ‘튜링 머신(Turing machine)’에 대해 들어본 적이 있을 것이다. 이것은 튜링의 이름을 딴 상상 속의 기계이다. 비록 튜링 머신은 이론적인 기계에 불과했지만, 후에 이 기계는 현대 컴퓨터로 시뮬레이션 되었고 누군가가 실제로 튜링 머신을 만들었다. 이어 수학에서 튜링 머신의 정의에 대해서도 살펴보고자 한다. 수학에서는 튜링 머신을 7개의 속성으로 설명한다. 바로 이 7개의 속성이 유일하게 한 대의 튜링 머신을 결정한다. 7개의 속성은 좀 많아 보이지만 2개의 속성이 대표적이다. 첫 번째 속성 : 기호(symbol) 집합, 즉 이 튜링 머신은 종이테이프 위의 정보를 읽고 쓰는데 기호의 종류는 한정되어 있다. 모든 기호의 종류를 튜링 머신의 ‘기호 수’ 또는 ‘색상 수’라고 하며 줄여서 ‘색 수’라고 한다. 여기서 기호의 구체적인 모양은 상관없고, 우리는 단지 몇 가지 기호가 있는지에만 관심이 있다. 또한 ‘공백’이라는 이름의 기호가 있는데, 바로 종이테이프가 비어 있다는 것을 의미한다. 이런 ‘공백’도 일종의 기호라고 할 수 있는데, 기호 집합에 포함된다. 따라서 일반적인 기호 집합에는 적어도 두 개의 원소가 있으며, 그중 하나는 공백 기호이다. 두 번째 속성 : 상태(state) 집합, 즉 튜링 머신은 어떤 상태에 있으며 유한이다. 모든 상태 유형의 수를 튜링 머신의 ‘상태 수’라고 한다. 마찬가지로 구체적으로 각각의 상태가 어떤 의미를 나타내든 상관없고, 단지 몇 가지 상태가 있는지에만 관심이 있으며 한 가지 상태의 튜링 머신도 허용된다. ‘공백’ 기호와 유사하게 ‘정지’라는 상태가 있는데, 튜링 머신의 연산이 끝나고 기계가 멈춘 상태이다. 그러나 이러한 상태는 일반적으로 상태 집합에 포함되지 않는다. 이 두 가지는 튜링 머신의 가장 주요한 속성이다. 나머지 다섯 가지 속성은 다음과 같다. 세 번째 속성: 앞에서 언급한 공백 기호이다. 종이테이프의 각 부분 정보의 경계가 어디에 있는지 구별할 수 있는 공백 기호의 존재가 필요하다. 이 책에서 ‘정보 엔트로피’를 이야기할 때 언급했는데, 만약 기호가 하나밖에 없다면 그것은 정보를 전달할 수 없다. 네 번째 속성: 초기 입력, 즉 튜링 머신이 실행되기 전 종이테이프의 기호 상태이다. 다섯 번째 속성: 초기 상태, 즉 튜링 머신이 작동하기 전에 내부에 위치한 어떤 상태이다. 어떤 순간에도 튜링 머신은 한 상태만 가능하다. 여섯 번째 속성: ‘수용 상태’, 또는 ‘종료 상태’라고 하는데, 즉 튜링 머신이 이 상태로 들어가면 정지한다. 많은 경우 수용 상태는 앞서 언급했던 정지 상태 한 가지뿐이다. 일곱 번째 속성 : 전이 함수의 집합이다. 전이 함수는 튜링 머신의 변화 과정을 결정하는 컴퓨터 프로그램과 매우 유사하다. 어느 시각에나 튜링 머신이 처한 상황은 두 가지 속성 즉, 현재 읽기 헤드의 작은 격자 안에 있는 기호와 내부 상태를 결정한다. 전이 함수는 입력 인자와 출력 인자가 있는 함수이며, 입력 매개 변수는 이 두 속성의 값을 취하며, 출력 매개 변수는 다음과 같이 3개이다. 1. 현재 격자에 출력된 기호 2. 내부 상태의 변화 3. 읽기 헤드가 방향을 바꾸거나 멈춤 모든 전이 함수의 집합은 튜링 머신이 작동에서 정지될 때까지의 과정을 결정한다. 물론 몇몇 상태의 순환에 들어가거나 읽기 헤드가 오른쪽으로 영원히 이동하는 상황 등에서는 튜링 머신은 멈추지 않는다. 튜링 머신의 계산 능력이 매우 저조하고, 의미 있는 계산을 완료하기 위해서 의미 있는 전이 함수의 집합을 설계하는 것이 더욱 어렵다는 것을 알 수 있다. 그러나 묘하게도 튜링은 모든 1차 논리의 수학적 명제가 하나의 튜링 머신으로 전환될 수 있다는 것을 증명했다. 명제의 참과 거짓은 이 튜링 머신이 정지 상태에 들어갈 수 있는지 여부에 달려 있다. 만약 정지되었다면, 우리는 이 튜링 머신 출력에서 이 명제의 참, 거짓을 알 수 있다. 모든 수학 명제는 하나의 숫자에 대응하는데 튜링은 ‘만물은 모두 튜링 머신’임을 증명하는 것 같다. * * * 본 정보는 도서의 일부 내용으로만 구성되어 있으며, 보다 많은 정보와 지식은 반드시 책을 참조하셔야 합니다. |
||
 |
고객의 행동을 유도하는 인스타그램 사진 잘 찍는 법 |
|
| 저자 박찬준 출판 나비의활주로 출간 2023.07 |
||
| 내 상품, 우리 회사 브랜드의 가치를 한 장의 사진에 담아내는 특급 노하우 |
||
 |
남의 시선에 아랑곳하지 않기 |
|
| 저자 차이웨이 출판 미디어숲 출간 2024.03 |
||
| 유리 멘탈에서 다이아몬드 멘탈로! |
||
 |
오늘날 혁명은 왜 불가능한가 |
|
| 저자 한병철 (지은이), 전대호 (옮긴이) 출판 김영사 출간 2024.01 |
||
| 디지털화한 세상, 철학적 봉기를 꿈꾸는 한병철의 글과 말 |
||
 |
Read Write Own: Building the Next Era of the Internet |
|
| 저자 Chris Dixon 출판 Random House 출간 2024.01 |
||
| TRENDS & BRIEFINGS
|
||
 |
첨단 자동화의 시대를 활짝 열고 있는 2020년대 |
|
| 오늘날 세계는 100년에 한 번 있는 문화, 기술, 지정학, 인구학적 변화의 한가운데 있다. 그리고 이 과정에서 경제와 사회는 뒤흔들리고 있다.... | ||
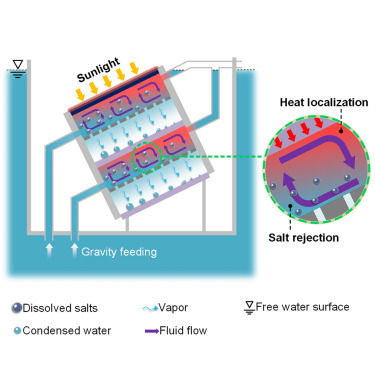 |
[GT] 바다의 원리를 이용한 새로운 ‘해수 담수화 기술’ |
|
| MIT와 중국 상하이 자오퉁 대학교(Shanghai Jiao Tong University)의 엔지니어들이 바다에서 영감을 받아 태양으로부터 전력... | ||